Добрый день!
Я пишу софт для управления умным домом голосом без интернета и использования внешних голосовых помощников, целевая платформа написанного софта Android/Windows/Linux. Сейчас приступаю к написанию парсера сообщений MQTT для поддержки оборудования WB, необходима помощь с данными для минимизации ошибок в написании парсера сообщений.
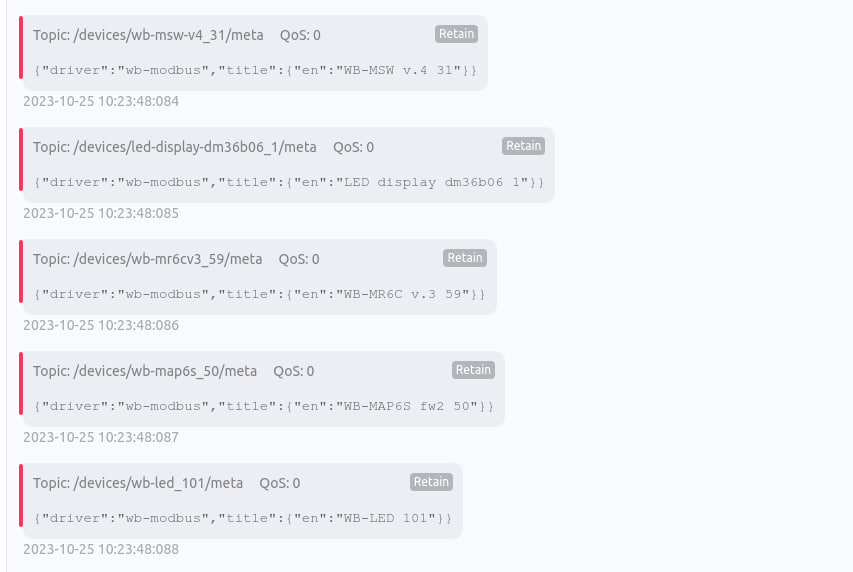
Для получения списка оборудования в чате посоветовали подписаться на топик :
/devices/+/meta
Пример вывода:
Хотелось бы получить такого рода вывод с тестового стенда с максимальным списком оборудования WB.
На сколько можно заложиться на поле … “title”: { “en”: DEVICE_TITLE, // English title of the device … для определения модели устройства. Так как в примере есть информация кроме названия устройства и возможно ли изменение этого поля пользователем?
Так же интересуют максимальные примеры для топика /devices/+/controls/+/meta по оборудованию WB для написания парсера по контролам.
Конструктор получается пластичный и нужно ориентироваться уже на конкретные доступные controls. Печально, что модель устройства в метаинформации жестко не зашита, было бы {“driver”:“wb-modbus”,“title”:{“en”:“WB-MWAC 11”}, “model”:“WB-MWAC”}, можно было бы отобразить у меня в интерфейсе картинку устройства.
А для чего, собственно?
Тут дело в том что взаимодействие (аппаратное) контролов внутри самого модуля определяется его настройками. То есть например может вход 1 - управлять выходом 1. А может управлять выходами 3 и 4, причем выход 3 будет переключаться а выход 4 - выключаться при каждом срабатывании. А может и никак не взаимодействовать с выхоами - предполагая программную обработку.
То есть модель, в общем - не сильно полезна.
Все на откуп проектировщику и наладчику.
Это понятно. Просто для UI составляющей процесса добавления устройства в моём ПО было бы красиво отображать иконку соответствующего железа. Но мне не на что завязаться, чтобы определить иконку устройства для отображения в UI.
Лучше выбор иконки отдать настройику. А еще могут быть совершенно произвольные устройства, например виртуальные или сторонние. Ну или zigbee, у которых контролы могут появляться -пропадать.
Есть иконки физических устройств, где я хотел именно отображать по модели реальные устройства. А есть пользовательские, которые отображаются в виджетах использования. Это разные экраны и это уже раздел UI/UX, который за мной, как за овнером создаваемого продукта.
// Units. ASCII string. Could be set only for type "value"
"units": "W",
// Maximum allowed control's value
"max": 100,
// Minimum allowed control's value
"min": -100.1,
// Control's value is rounded to defined precision by a driver and it is also used during user input validation
"precision": 0.1,
// Display order in user interface
"order": 10,
// The control doesn't have /on topic
"readonly": true,
"title": {
"en": CONTROL_TITLE, // English title of the control
"ru": CONTROL_TITLE_RU, // Russian title of the control
...
}
}
А к этому есть примеры или четкие описания, что является опциональными параметрами, а что обязательными? Просто к примеру “units” опциональный и есть у типа “value”, а с другими вопрос, будет ли к примеру precision присутствовать в ответе для типа text? Просто при парсинге Json и маппинге его в объект это критичное знание.
Оно не проектировалось под такое — «устройства», это просто некие сущности и они не обязательно могут быть физическими, как сказал коллега.
Если вам это очень нужно, вы всегда можете форкнуть наш драйвер, запрограммировать в нём любую желаемую функциональность и использовать свою сборку в своих проектах.
Цель моего софта, сделать удобное приложение для панелек/планшетов на android для управления голосом и с экрана умным домом любой домохозяйкой. Форки это уже усложнение пользовательского опыта. Просто пока эту фитчу не будем делать, а потом может как-то и украсим физические устройства для удобства навигации в закладке настроек.
Тогда знание об устройствах в щите вообще довольно бесполезная информация - она нужна только на этапе ПНР и это делает точно не домохозяйка. Домохозяйке нужны понятные абстракции: люстра, сценарий, потеплее.
В целом все поля опциональные. Сам топик /meta тоже может отсутствовать. Нет требований о том, что в зависимости от type обязательно должны быть какие-то поля. Но для некоторых типов только определённые параметры имеют смысл. Например, для rgb нет смысла в precision.
Думаю, что логика должна быть следующей.
Проверить наличие типа в /meta, если его нет, то наличие топика /meta/type, если его тоже нет, то это тип text.
Для типов составить список параметров, которые имеют смысл, и то, как интерпретировать их отсутствие.
Прочитать доступные параметры из /meta и выбрать те, что имеют смысл согласно п.2. Если нет /meta, смотреть наличие /meta/min, /meta/max, /meta/order, /meta/readonly.
Сочетание п.2 и п.3 даст информацию об ограничениях и том, как стоит отобразить конкретный контрол.
Поля. Очень плохо, что все поля по сути опциональны, как минимум одно поле “readonly” должно быть обязательным, чтобы мы, сторонние разработчики софта, знали можно ли писать в данное устройство или только читать. Для других типов, если поле опционально, то должно быть зафиксировано в типе дефолтные значение.
Сам топик /meta тоже может отсутствовать. Для меня как разработчика стороннего софта, если топик отсутствует, то согласно конвенции оборудование не существует.
По мне, если производитель заявил конвенцию, то в своем оборудовании он должен её соблюдать. Сейчас основная причина проблем именно в несоблюдении конвенции самим производителем, я не говорю о легаси, а о сравнительно новых параметрах.
К примеру:
В типе “range” заявлены только целочисленные параметры, а присылаются числа с плавающей запятой.
Объявление явных параметров с целочисленными параметрами в оборудовании как тип с плавающей заятой. В примере ниже явно лучше было объявить range c min и max.
/devices/wb-mr6c_123/controls/Input 6 Single Press Counter/meta {“order”:13,“readonly”:true,“title”:{“ru”:“…”},“type”:“value”}
/devices/wb-mr6c_123/controls/Input 6 Long Press Counter/meta {“order”:14,“readonly”:true,“title”:{“ru”:“…”},“type”:“value”}
Парсер я написал, который думаю покроет сейчас 85% кейсов, но хотелось бы, что бы производитель по максимуму не отходил от своей же заявленной конвенции и привел значения в своих шаблонах к ней.
Если работать с JSON-строками, как с объектами, то нет никакой проблемы кодировки. Да и перекодировки строк там нет — это сериализация так работает.
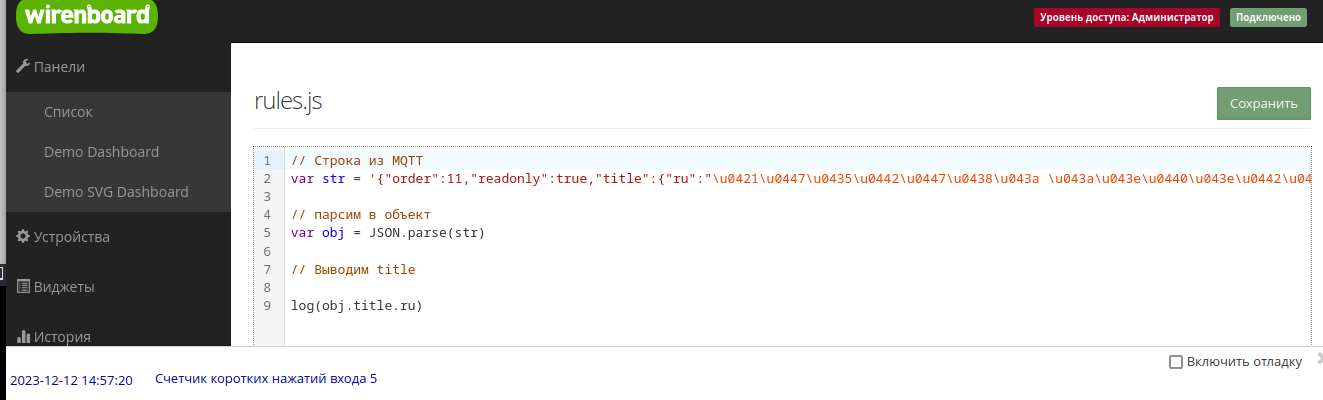
Вот пример разбора вашего сообщения на JS, можно запустить как правило на wb-rules:
// Строка из MQTT
var str = '{"order":11,"readonly":true,"title":{"ru":"\u0421\u0447\u0435\u0442\u0447\u0438\u043a \u043a\u043e\u0440\u043e\u0442\u043a\u0438\u0445 \u043d\u0430\u0436\u0430\u0442\u0438\u0439 \u0432\u0445\u043e\u0434\u0430 5"}}'
// Парсим в объект
var obj = JSON.parse(str)
// Выводим title
log(obj.title.ru)
Я говорю о двойной, так как получаемая строка из MQTT брокера сама по себе уже является строкой в кодировке UTF-8. А внутри неё опять происходит кодировка одного из параметров в UTF-8. Причем такому двойному кодированию (сериализации) подвержены не все русскоязычные строки, которые имеются в брокере от оборудования Wirenboard.